Perquisites
Start Rabbit With delay message exchange plugin enabled
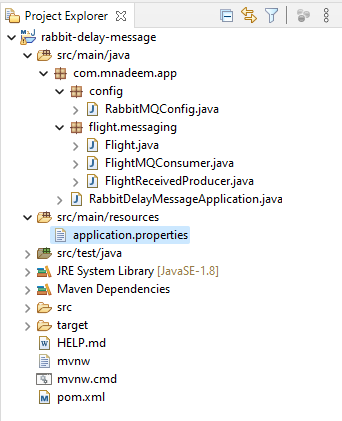
Create Project
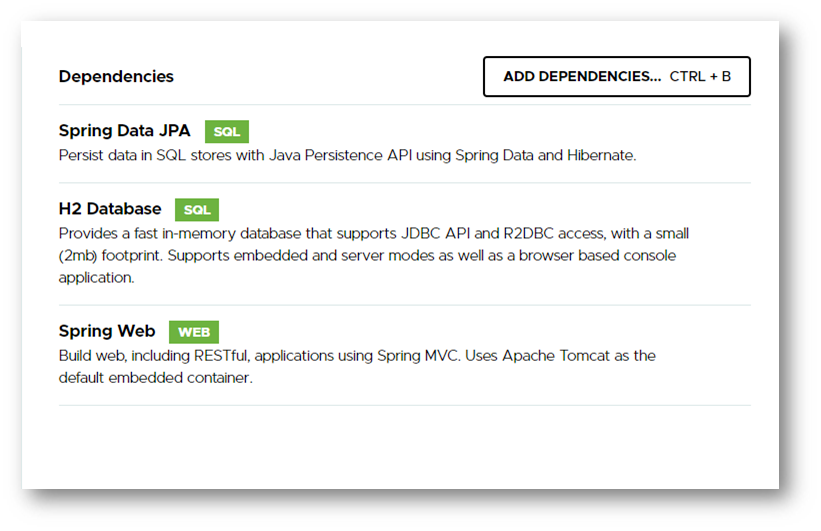
Create Boot project with following dependencies
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
</dependency>
application.properties
# Rabbit
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
rabbitmq.flight.dg.exchange=otel_flight_direct
rabbitmq.flight.received.routingkey=flight.event.received
rabbitmq.flight.received.queue=flight.received.queue
RabbitMQConfig.java
import java.util.HashMap;
import java.util.Map;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.CustomExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RabbitMQConfig {
private static final String EXCHANGE_TYPE_DELAY = "x-delayed-message";
private static final String EXCHANGE_TYPE_DELAY_ARGUMENT = "x-delayed-type";
private static final String EXCHANGE_TYPE_DELAY_ARGUMENT_DIRECT = "direct";
@Value("${rabbitmq.flight.dg.exchange}")
private String exchange;
@Value("${rabbitmq.flight.received.queue}")
private String flightQueue;
@Value("${rabbitmq.flight.received.routingkey}")
private String flightRoutingKey;
@Bean
CustomExchange directExchange() {
Map<String, Object> args = new HashMap<>();
args.put(EXCHANGE_TYPE_DELAY_ARGUMENT, EXCHANGE_TYPE_DELAY_ARGUMENT_DIRECT);
return new CustomExchange(exchange, EXCHANGE_TYPE_DELAY, true, false, args);
}
@Bean(name = "flightReceived")
Queue flightReceivedQueue() {
return new Queue(flightQueue, true);
}
@Bean
Binding flightReceivedBinding(@Qualifier("flightReceived") Queue queue, CustomExchange exchange) {
return BindingBuilder
.bind(queue)
.to(exchange)
.with(flightRoutingKey)
.noargs();
}
@Bean
RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory, Jackson2JsonMessageConverter converter) {
final RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);
rabbitTemplate.setMessageConverter(converter);
return rabbitTemplate;
}
@Bean
Jackson2JsonMessageConverter producerJackson2MessageConverter() {
return new Jackson2JsonMessageConverter();
}
}
Flight.java
import java.time.LocalDateTime;
import com.fasterxml.jackson.databind.annotation.JsonDeserialize;
import com.fasterxml.jackson.databind.annotation.JsonSerialize;
import com.fasterxml.jackson.datatype.jsr310.deser.LocalDateTimeDeserializer;
import com.fasterxml.jackson.datatype.jsr310.ser.LocalDateTimeSerializer;
public class Flight {
private String origin;
private String destination;
private String airline;
@JsonSerialize(using = LocalDateTimeSerializer.class)
@JsonDeserialize(using = LocalDateTimeDeserializer.class)
private LocalDateTime departureTime;
public String getOrigin() {
return origin;
}
public void setOrigin(String origin) {
this.origin = origin;
}
public String getDestination() {
return destination;
}
public void setDestination(String destination) {
this.destination = destination;
}
public String getAirline() {
return airline;
}
public void setAirline(String airline) {
this.airline = airline;
}
public LocalDateTime getDepartureTime() {
return departureTime;
}
public void setDepartureTime(LocalDateTime departureTime) {
this.departureTime = departureTime;
}
@Override
public String toString() {
return "Flight [origin=" + origin + ", destination=" + destination + ", airline=" + airline + ", departureTime="
+ departureTime + "]";
}
}
FlightReceivedProducer.java
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.amqp.AmqpException;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.core.MessagePostProcessor;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
@Component
public class FlightReceivedProducer {
private static final Logger LOGGER = LoggerFactory.getLogger(FlightReceivedProducer.class);
@Autowired
private RabbitTemplate rabbitTemplate;
@Value("${rabbitmq.flight.dg.exchange}")
private String exchangeName;
@Value("${rabbitmq.flight.received.routingkey}")
private String routingKey;
public void sendMessage(Flight flight) {
try {
rabbitTemplate.convertAndSend(exchangeName, routingKey, flight, new MessagePostProcessor() {
@Override
public Message postProcessMessage(Message message) throws AmqpException {
message.getMessageProperties().setDelay(1000);
return message;
}
});
LOGGER.debug("Sent message for flight");
} catch (Exception e) {
LOGGER.error("Unable to send Message ", e);
}
}
}
FlightMQConsumer.java
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
@Component
public class FlightMQConsumer {
private static final Logger LOGGER = LoggerFactory.getLogger(FlightMQConsumer.class);
@RabbitListener(queues = "#{'${rabbitmq.flight.received.queue}'}")
//public void consumeMessage(Flight flight, @Header(name = "receivedDelay", required = false) Integer delay) {
public void consumeMessage(Flight flight, Message message) {
try {
LOGGER.trace("Message received, after delay of {} : {}", message.getMessageProperties().getReceivedDelay(), flight);
} catch (Exception e) {
LOGGER.error("Unnable to process the Message", e);
}
}
}
RabbitDelayMessageApplication.java
import java.time.LocalDateTime;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import com.mnadeem.app.flight.messaging.Flight;
import com.mnadeem.app.flight.messaging.FlightReceivedProducer;
@SpringBootApplication
public class RabbitDelayMessageApplication implements CommandLineRunner {
@Autowired
private FlightReceivedProducer producer;
public static void main(String[] args) {
SpringApplication.run(RabbitDelayMessageApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
producer.sendMessage(flight());
}
private Flight flight() {
Flight flight = new Flight();
flight.setAirline("1");
flight.setDepartureTime(LocalDateTime.now());
flight.setDestination("d");
return flight;
}
}
Run the Application
Message delivered to exchange immediately, however delivered to queue after the delay.


Exchange Definition
{
"name": "otel_flight_direct",
"vhost": "/",
"type": "x-delayed-message",
"durable": true,
"auto_delete": false,
"internal": false,
"arguments": {
"x-delayed-type": "direct"
}
}